
Un des aspects qui freinent le développement du machine learning, est que le traitement des données non-structurés est encore très peu exploré. On collecte chaque jour des milliers de données sonores rien qu’avec tous les appels téléphoniques, les musiques, les enregistrements sonores ou les vidéos. La question de savoir ce que l’on peut tirer de ces données se pose.
Lorsque j’étudie la data science en cours ou à travers les formations en ligne, les cours ont tendances à être un peu trop idéalistes. On nous présente des données propres, fiables normalisées, toutes récoltées dans les mêmes conditions.
Malheureusement nous ne sommes pas dans le monde des bisounours ! Les données dont on dispose sont non-structurées, biaisés, non-uniformes et toutes ces choses rendent le travail beaucoup plus difficile. D’ailleurs, en data science, la conception du modèle est une des dernières choses que l’on fait et elle ne représente qu’une petite part du travail.
Concernant les données sonores, on dispose souvent de bandes sons bruitées, de longueurs différentes, la façon de parler des personnes n’est pas la même, les enregistrements ne sont jamais faits dans les mêmes conditions, etc. Tirer des résultats intéressants de données sonores semble donc être un challenge sérieux.
Séries temporelles pour la représentation numérique de données sonores
La question de la classification ou du clustering des données sonores est un sujet courant de recherche en machine learning. En mathématiques, lorsqu’on a deux objets du ‘’même type’’ (des bandes sons dans notre cas), on aime bien mesurer leur degré de similitude, on appelle souvent ça distance.
La mesure de la distance entre deux sons peut se faire de différentes manières. Pour expliquer ces méthodes, il convient d’abord de définir ce qu’est un son d’un point de vue mathématique.
Un son est un signal, définit par une amplitude variable et une fréquence. C’est quelque chose qui se modélise par une fonction temporelle.
Vous savez peut-être déjà qu’en informatique, les fonctions sont modélisées par une suite de valeurs numériques. Lorsque cette suite dépend du temps, on parle de série temporelle.
Les séries temporelles servent à modéliser l’évolution du court d’une action en bourse, l’évolution de la météo, ou quoique ce soit d’autres qui dépend du temps. L’objectif du traitement des séries temporelles est souvent de déterminer des tendances en essayant d’extrapoler les courbes pour prévoir l’évolution d’un phénomène.
Maintenant que l’on sait qu’un son est représenté par une série temporelle, nous pouvons revenir à notre problème de classification. Comme je l’ai déjà expliqué, en classification tout repose sur le calcul de la distance entre deux objets (leur degré de similitude).
Il existe plusieurs méthodes pour mesurer la distance entre deux séries. Celle que j’ai choisi de vous présenter est DTW. Dynamic Time Warping (ou Déformation Temporelle Dynamique en français)
Un des algorithmes les plus utilisés est DTW, pour Dynamic Time Warping. Les données sonores dont on dispose sont souvent hétérogènes : elles n’ont pas les mêmes longueurs, les sons ne sont pas enregistrés dans les mêmes conditions, pas aux mêmes fréquences, tout cela rend l’étude plus complexe. DTW permet de résoudre en partie ce problème.
Là où un calcule de distance entre deux séries classique (la distance euclidienne typiquement) permettra de comparer les deux séries temporelles points par points, DTW permet de comparer un point avec plusieurs autres points de l’autre série. Cette approche permet de trouver l’alignement optimal entre les deux séries et elle est assez intuitive. Cette image vous permet de mieux comprendre de quoi on parle :

La méthode DTW repose sur le calcul d’une matrice appelée matrice des distances. Cette matrice (que je vais noter D) est calculée de la façon suivante :
Soient les deux séries temporelles que l’on souhaite comparer t et r, on note leurs longueurs respectivement m et n
1. On considère la matrice D comme étant de taille m par n. L’élément d’indices (i,j), que je note D(i,j), donne la distance DTW entre ( ti , … ,tm ) et ( rj, … ,rn )
2. On calcul chacune des valeurs de la matrice de façon récursive 😀 ( i , j ) = | t ( i ) − r ( j ) | + m i n { D ( i + 1 , j ), D ( i + 1 , j + 1 ), D ( i , j + 1 ) } ,
Avec la condition initiale suivante :
D ( m , n ) = | t ( m ) − r ( n ) |
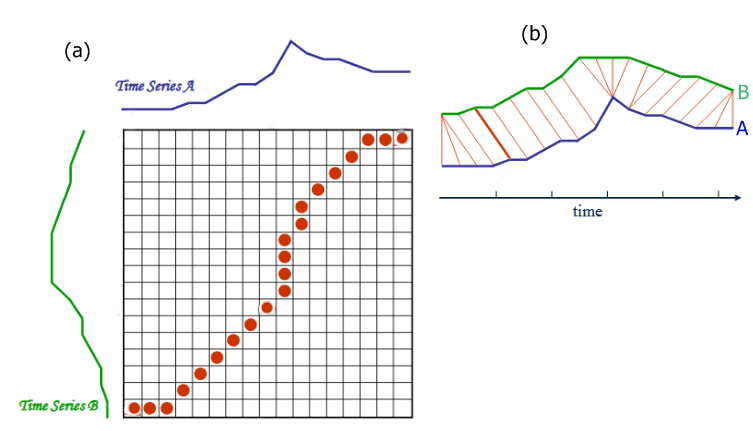
3. Une fois la matrice obtenue, on peut calculer la distance simplement à l’aide d’une somme. On part de la première case en haut à droite de la matrice D et on se déplace sur la case dont la valeur est la plus faible parmi la case de gauche, la case du bas et la diagonale à gauche. Et on additionne les valeurs qui correspondent aux cases du chemin trouvé (en rouge sur l’image ci-dessus).
Il faut savoir qu’il existe des fonctions déjà disponibles sur Python (fastdtw par exemple) pour comparer deux séries, vous n’avez pas besoin de connaître ces calculs mais c’est toujours mieux de savoir d’où ça vient.
DTW est essentiellement utilisé pour la reconnaissance vocale.
On peut aussi l’utiliser pour classifier des sons, par exemple détecter de façon complètement automatique à quelle genre une musique appartient.
Il existe d’autres méthodes de comparaison entre deux séries temporelles. On pourrait aussi utiliser l’approche de Longest common subsequence qui repose sur le fait que plus deux séries temporelles ont de séquences de valeurs en commun, plus elles se ressemblent.
De façon concrète, pour classifier les sons on calcul les distances entres les différentes bandes sons dont on dispose, en utilisant l’une des méthodes énoncés, puis on utilise un algorithme de classification au choix. Personnellement j’aime bien Dynamic Time Warping, c’est facile à coder, fiable et l’exécution n’est pas trop longue pour des audios de tailles raisonnables, mais cela doit certainement dépendre de l’application.
Références : [1] Dynamic Time Warping review, Pavel Senin
[2] Dynamic Time Warping with time series, Sachia Kyaagba (Medium.com)
[3] Explication mathématique de DTW, mirlab.org



Laisser un commentaire