
Il y a quelques semaines, nous vous proposions une introduction à l’apprentissage non supervisé. Grand concept du machine learning, il permet à un ordinateur d’en apprendre lui-même sur les données que l’humain lui fournit.
Concrètement, les algorithmes non supervisés repèrent des similarités dans les données pour pouvoir ensuite les structurer. Par exemple ils peuvent étudier les similarités entre individus, ce qui rend possible leur division en différents groupes. Ce partitionnement des individus est appelé clustering.
Comment fonctionnent les méthodes de clustering ?
Avant que l’intelligence artificielle des ordinateurs ne devienne capable de détecter des similarités entre individus, ce sont bien des intelligences humaines qui ont implémenté les algorithmes de clustering.
Il en existe plusieurs dizaines, dont voici plusieurs grandes catégories.
Pour chaque méthode, il est nécessaire de choisir comment mesurer la similarité entre deux individus – qu’on peut imaginer comme deux points de l’espace des réels en dimension p.
Il nous faut donc une fonction distance, comme par exemple la distance euclidienne. Les n individus sont des « points » de l’espace de variables R en dimension p.
Les méthodes de clustering hiérarchiques
Les méthodes de clustering de type hiérarchique sont différentes. Elles forment pas à pas des connexions entre individus (pour les méthodes de clustering hiérarchiques ascendantes), et utilisent une matrice de distances entre individus pour trouver le regroupement le plus proche d’un autre.
En pratique, on part de n ensembles qui sont les individus en tant que singletons. La première connexion se fait donc entre les deux individus les plus proches.
Pour débuter la deuxième étape, il faut mettre à jour la matrice des distances en enlevant une case, à cause du regroupement de deux individus. Mais comment calculer la distance d’un ensemble à un autre s’il n’est pas un singleton ? C’est justement un des choix à effectuer au départ : la stratégie d’agrégation. Il y en a de multiples, les plus simples étant de choisir la distance minimale entre les individus des deux groupes (single linkage), maximale (complete linkage) ou bien moyenne (average linkage).
A la fin de cette deuxième étape, on connecte donc les deux groupes les plus proches. Et ainsi de suite pour les étapes suivantes, jusqu’à connecter les deux derniers groupes qui recouvrent tous les individus.
Les connexions successives se représentent sur un dendrogramme (cf illustration). La distance associée à chaque connexion se trouve sur l’axe y de celui-ci.
L’algorithme se termine bien sûr par le choix de nos clusters. Là encore, le critère n’est pas unique : on peut en vouloir un nombre précis, ou bien fixer un critère de distance inter-classe. On utilise le dendrogramme pour mettre les clusters en évidence.
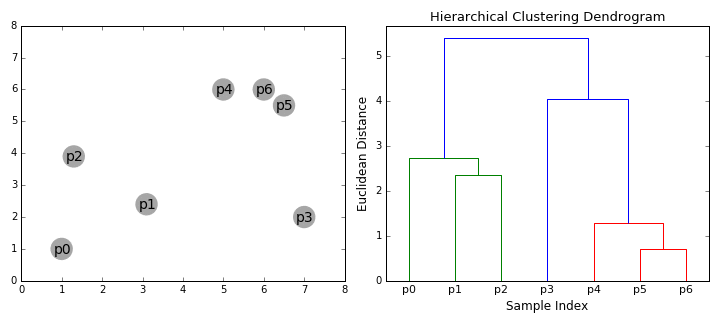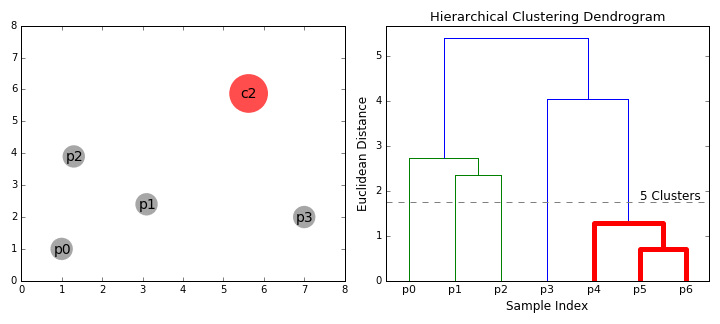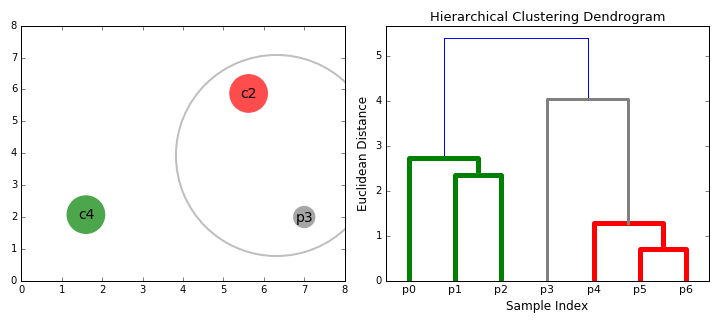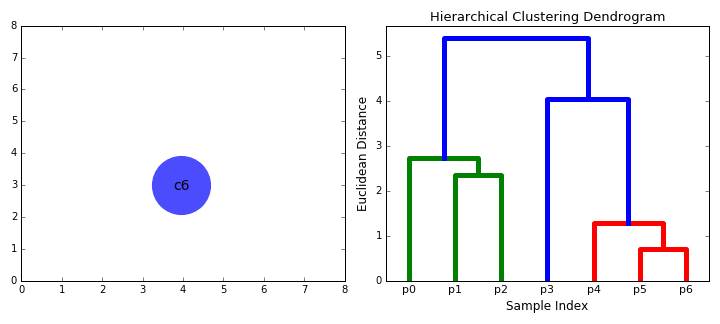
A gauche, les individus représentés dans R2. A droite, le dendrogramme associé et les étapes de sa création. Si on souhaite deux classes, on choisira (p0,p1,p2) et (p3,p4,p5,p6). Si on souhaite des classes éloignées de plus d’une unité de mesure, on choisira (p0,p1,p2), (p3) et (p4,p5,p6). Animation : dashee87.github.io
Les méthodes centroïdes
La méthode centroïde la plus classique est la méthode des k-moyennes. Elle ne nécessite qu’un seul choix de départ : k, le nombre de classes voulues.
On initialise l’algorithme avec k points au hasard parmi les n individus.
Ces k points représentent alors les k classes dans cette première étape. On associe ensuite chacun des n-k points restants à la « classe-point » qui lui est la plus proche. A la fin de cette première étape, chaque classe est caractérisée par la moyenne des valeurs de chacun de ses individus. On a k moyennes pour k classes.
La deuxième étape consiste à évaluer la distance de chaque individu à chacune des k moyennes. Certains individus peuvent ici changer de classe. A la fin de cette étape, on actualise les k moyennes. Et on réitère les étapes, jusqu’à ce qu’il y ait convergence pour obtenir nos k clusters finaux.
Ces classes finales dépendent souvent beaucoup des k individus choisis pour l’initialisation. C’est pourquoi certains algorithmes de kmeans itèrent plusieurs fois le processus avec des initialisations différentes, dans le but de garder la partition qui minimise le plus la variance intra-classe (somme des distances entre les individus d’une même classe).
Dans ce tutoriel NLP nous vous montrons comment utiliser la méthode kmeans pour classer des phrases de manière automatique.
Les autres algorithmes des méthodes centroïdes peuvent prendre en compte d’autres représentants de classes que la moyenne, comme le médoïde, individu le plus central du groupe.
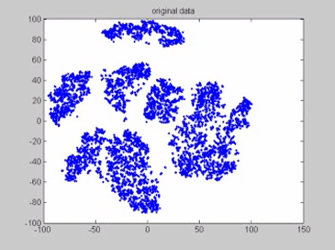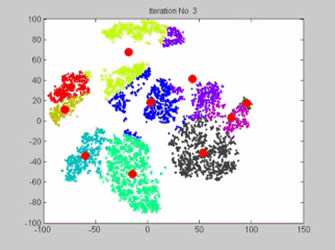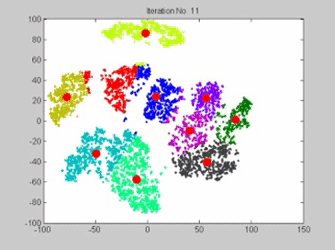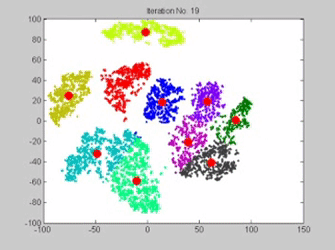
Les points rouges sont les centres des classes, actualisés à chaque étape. On observe bien le phénomène de convergence de ces 10 centres mobiles. Animation : www.analyticsvidhya.com
Les méthodes à densité
Les classes des méthodes à densité correspondent aux zones de densité relativement élevées, c’est-à-dire les zones où beaucoup de points sont proches par rapport à d’autres zones de l’espace R en dimension p (cf illustration).
La méthode phare de cette catégorie est appelée « density-based spatial clustering of applications with noise », DBSCAN. En plus de former des classes d’individus, l’algorithme repère par la même occasion les valeurs hors du commun que l’on qualifie de bruit.
Il prend deux paramètres en entrée : Ɛ la distance maximale qui peut définir deux individus comme voisins, et N le nombre minimal d’individus nécessaires pour former un groupe. A partir de là, l’algorithme est assez intuitif. On aura besoin de stocker deux informations : les clusters successifs et les individus visités au fur et à mesure.
La première étape consiste à choisir un point parmi les n disponibles. Grâce au paramètre Ɛ, on peut définir le voisinage du point initial, c’est-à-dire l’ensemble des points que l’on peut qualifier comme ses voisins.
– Et grâce au paramètre N, on peut dire que si cet ensemble est constitué de moins de N points, alors le point initial correspond à du bruit. On le stocke alors dans les individus visités.
– A l’inverse si le voisinage comprend plus de N points, alors on peut initialiser un cluster avec le point de départ. On étudie chaque point de son voisinage initial.
Et pour tout point de ce voisinage, si son propre voisinage comporte plus de N éléments, alors on étend le voisinage initial en le réunissant avec le voisinage du point visité.
Puis on ajoute ce point dans le cluster. Une fois que tous les points du voisinage ont été testés, ceux retenus dans le cluster sont stockés comme individus visités. Et le cluster obtenu est stocké dans la liste des clusters.
Tant que tous les individus n’ont pas été visités, on réitère cette étape en commençant par choisir un individu parmi ceux qui sont encore disponibles. Et on obtient finalement notre liste de groupes d’individus ainsi que les individus correspondant à du bruit.
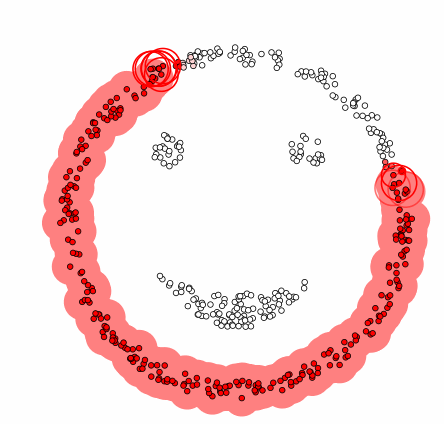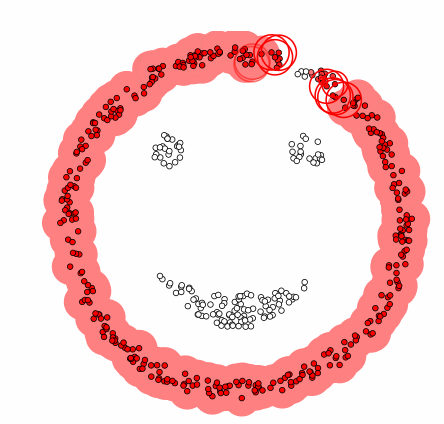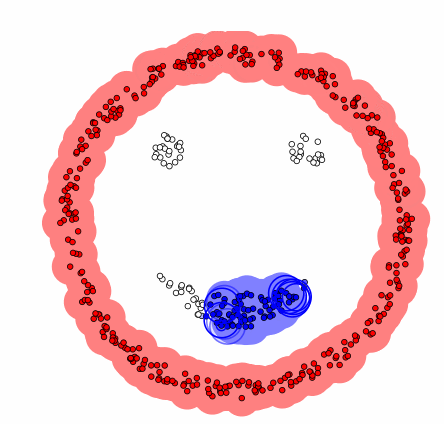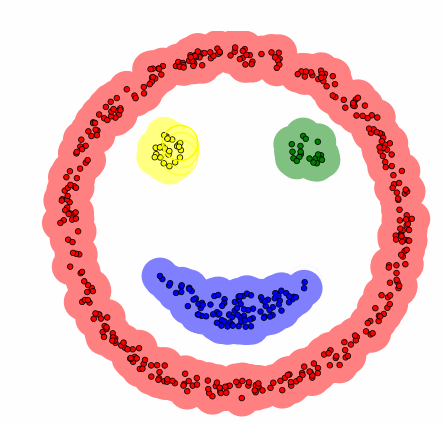
L’algorithme DBSCAN pas à pas. Les cercles en mouvement correspondent aux voisinages successifs. Il y a ici 4 zones où la densité est élevée. La forme des clusters s’adapte à la forme des données proposées. Animation : zhuanlan.zhihu.com
Au-delà de ces 3 catégories d’algorithmes, d’autres méthodes moins intuitives existent, comme la maximisation de l’espérance, qui repose sur des outils mathématiques probabilistes.
Il existe donc une multitude de façons de partitionner la population d’une base de données. Chaque méthode présente ses avantages mais aussi ses limites, selon le type de données à traiter.
Les méthodes hiérarchiques peuvent être gourmandes en calculs, la méthode des k-moyennes donne des groupes à la forme uniquement convexe, et pour chaque méthode les paramètres d’initialisation ne sont pas forcément optimaux… Sachant cela, l’objectif reste de minimiser les variances intra-classes tout en s’évitant des temps de calcul trop contraignants. Qu’est-ce qu’on ne ferait pas pour obtenir de bons clusters ?
Pour conclure, le partitionnement s’avère très utile pour explorer une base de données, mais il sert également à de nombreux domaines : comme par exemple dans la classification de données sonores.
Lorsque les données sont labellisées, on peut aussi faire de la classification avec des réseaux de neurones. Ces méthodes sont beaucoup plus efficaces, surtout lorsque l’on a beaucoup de données. Mais vous verrez dans l’article sur les réseaux de neurones, qu’elles ont aussi leurs contraintes…


la méthode des k moyenne, est ce qu’elle est applicable sur les données non-numérique?!
Bonjour. Vous avez quel type de données ? La méthodes des k-moyennes n’est pas applicables directement mais on a toujours des méthodes pour transformer les données en données numériques. On parle d’encodage. Par exemple pour des textes, on va utiliser des modèles comme Word2Vec ou Bert pour transformer le texte en vecteur.
Bonjour, quel algo conviendrait le mieux pour répartir des primes ? Exemple : j’ai une enveloppe de 1000€ et je dois la distribuer à 5 collaborateurs. Sachant que toute mes équipes ont 5 collaborateurs mais que le montant de la prime varie en fonction des services ?